今天主要介紹MongoDB Atlas Search,並且介紹Index的強大之處。第一部分會先介紹Search 和Find的差異,接著分享Search的建立和使用方法。最後會使用範例資料去比較有使用Index和沒有使用Index在搜索效率的差異。
在實習的過程中我就非常好奇明明有find功能可以利用條件篩選出相關想要的資訊,為什麼又要有一個Search的功能?因此我就去查詢相關資料來幫助我詳細了解兩者的差異,簡單解釋就是Find主要就是查找論文時的精準搜索,而Search算是模糊搜索。在應用場景上就有蠻大的區別,Find方法比較多用於查找結構化資料,像是顧客ID或者任何數據。可是Search方法常用於文字類型的查找,例如文本資料涵蓋特定關鍵字等等。此外,Find 方法可以不用建立index即可進行資料查詢,但是Search方法需要事先建立Search Index才可以進行查詢。所以接下來將要介紹如何建立Search Indexes,我這邊選擇用MongoDB Compass的UI介面去進行建立。
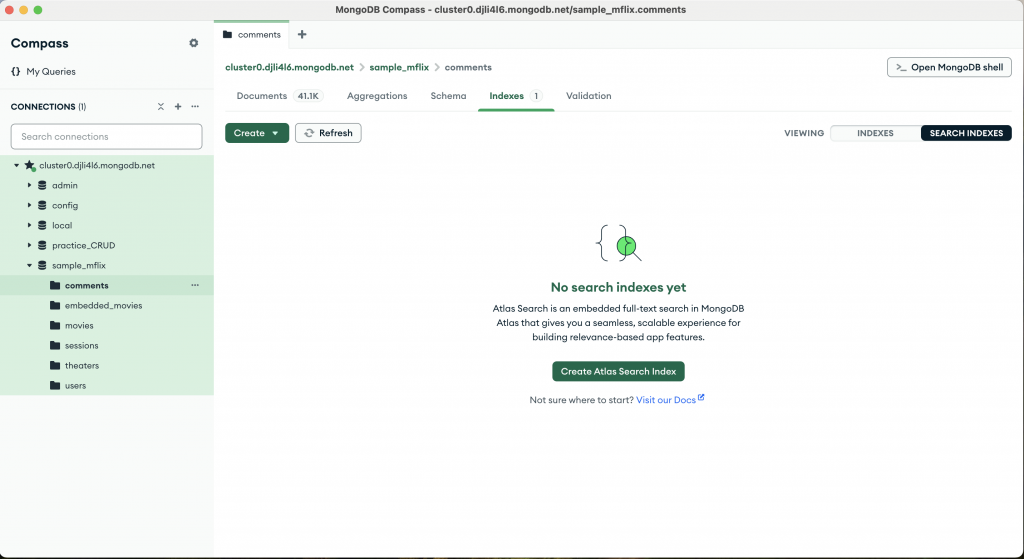
這邊我們使用範例資料去建立Search Index,選取sample_mflix 資料庫中的comments collection。選取上方中間的Indexes分頁,並在畫面右邊切換到Search Indexes。
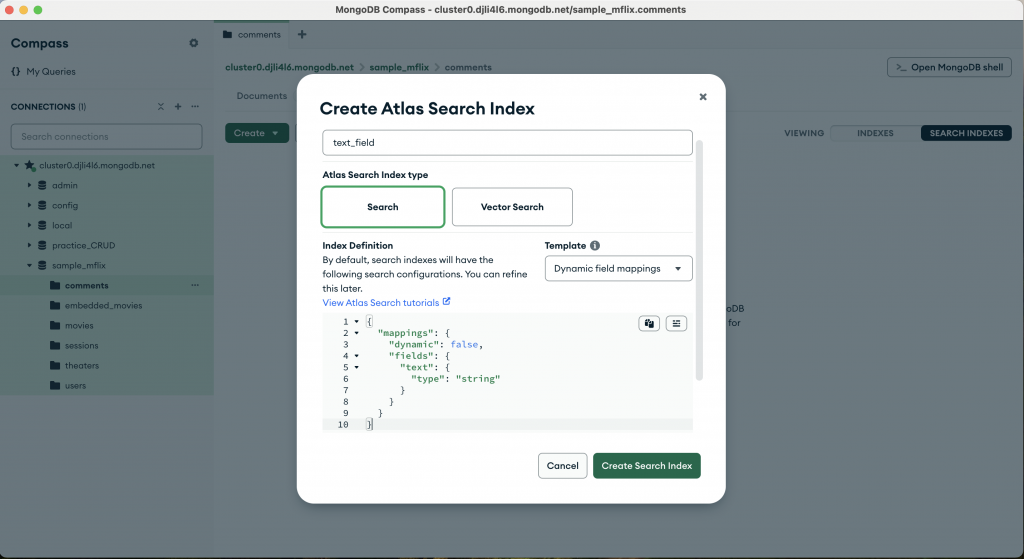
接著按照途中的Index definition 輸入Search Indexes的定義。可以看到這邊我們告知text這個欄位(field) 要建立Search Indexes,且欄位中的值是string。(這邊偷偷埋了一個伏筆,未來RAG要使用的Vector Search 也是利用這個方法來建立索引和檢索)
接著我們就來比較一下有建立Index 和沒建立Index在查詢時間上的差異。
先設定好我們要使用的database name 以及 collection name。
from pymongo import MongoClient
connecting_string = "your_connection_string"
client = MongoClient(connecting_string)
db = client['sample_mflix']
collection = db['comments']
import time
# 搜索關鍵字
search_term = "movie"
# 計時全文搜索
start_time = time.time()
# 使用MongoDB Atlas Search必須在MongoDB Atlas上設置好,這裡假設已經設置好名為'textSearchIndex'的索引
search_results = collection.aggregate([
{
"$search": {
"index": "textSearchIndex",
"text": {
"query": search_term,
"path": "text"
}
}
}
])
search_duration = time.time() - start_time
print(f"Search duration: {search_duration:.4f} seconds")
# 計時普通查找
start_time = time.time()
# 使用正則表達式進行普通查找,有符合search_term的資料(i 代表忽略大小寫)
find_results = collection.find({"text": {"$regex": search_term, "$options": "i"}})
find_duration = time.time() - start_time
print(f"Find duration: {find_duration:.4f} seconds")
# 關閉連接
client.close()
接著我們去比較Search 方法和find方法的用時差異,這邊先說明一下因為範例資料的text是亂碼,所以在查找結束後沒有結果是正常的。但是可以看到用時上的差異。
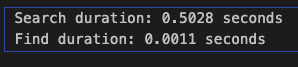
註1:在使用find方法時不會使用到Search Indexes
註2:aggregate方法是MongoDB 用來建立類似於查詢pipeline的用法,這裏只建立Search方法。都是為了要找到符合text_term的document。
由上可知,一樣的查詢目的使用不同的搜索方式在用時上就差異很大,目前這個測試的資料筆數只有四萬多筆,當資料再更龐大或者內容結構更複雜時,查詢的時間差異會更加明顯。因此建議大家未來若要建立查找系統,記得先建立Index來優化查詢!
(以上程式碼由GPT協助製作)

